We all know how entertaining and impactful movie trilogies are — The Godfather, The Dark Knight, The Apu, and many others. Trilogies are bound together by central themes while providing multiple perspectives to the audience.
In that sense, we will build on my previous blog on Threat Hunt Research Methodology to go through a trilogy of three powerful frameworks/paradigms that can help us in threat hunting.
We will explore the LAYER approach, which will provide you with a different paradigm in hunting, so buckle up, because this movie will be as fun as it is informative.
I will not go into in-depth details on the above frameworks, as the original authors have articulated them better than I can. All of them can complement each other by giving different perspectives to hunters, and combining them will address the limitation/gap between high-level abstract/broad categories/concepts (MITRE Tactics and Techniques) and catch-all procedures.
That combination, the LAYER approach, can help us to bridge that gap by breaking down the abstract strategic objectives to fundamental elements that can make up an implementation.
The LAYER approach has seven layers, and each level will help us understand an adversary’s behavior from their technical details to strategic context. Each layer will also help us in different phases of threat hunting, from planning to performing hunts within a dataset:
As we have recently seen the treasure trove of information on BlackBasta, let’s take that as an example to understand how we can use the LAYER approach in threat hunting to develop more resilient hunt strategies. By understanding adversary behaviors from an operational level, we can continuously adapt our hunting techniques.
There are many things in those chat leaks, but one thing that stood out to me due to its popularity in recent conversations is the EDR “bypass” technique. We must recognize that these techniques don’t exist in a vacuum. They operate within specific conditions (the environment) and contexts (their position in the attack chain), and build upon historical methods (the evolution of EDR evasion).
🔔 I would like to note that there are other ways to bypass EDR, like creating WEF rules (EDRSilencer), host file manipulation, name resolution policy table, etc. We will review a couple of them to see how these concepts apply and give you something to ponder on other techniques and procedures mentioned in the chat leaks. For other actors, these may not be in their arsenal at all, as they might take other “routes” to achieve their “goal” (I’m looking at you, security camera).
Let’s jump into chat leaks. I used the BlackBastaGPT to get this info by focusing on EDR bypass conversations in the leaks. By doing so, we can learn their techniques, how they were used, and their implications. We can see that “EDR bypass” is applied in Initial Execution, Post-Exploitation, Privilege Escalation, Lateral Movement, Persistence, and Defense Evasion.
OK, there are several ways discussed to “bypass” EDR, and research articles have been published on doing it outside of this.
What does it mean for us in threat hunting? Well, with the face value, nothing really, at least just with the above information. Treating “EDR bypass” as a single technique to hunt for might leave massive blind spots in our research and hunt methodology, and this ambiguity reveals a fundamental challenge. As “EDR bypass” is a technique in the “Impair defenses” Tactic, we can never “hunt” for it without knowing its actual implementation or understanding multiple ways to compare and contrast.
In the next blog, we will go through a practical example on how we can apply our LAYER approach.
Recently Fortinet released an advisory stating two CVEs (CVE-2024–55591 and CVE-2022–40684) were actively exploited in the wild. I started looking from a Threat hunt perspective but as there are few details in the advisory to map out the overall picture — I began to turn to adversary infra analysis in hopes of finding connections to expand observables and patterns. From IOCs from a Fortinet advisory, it expanded to correlation with Arctic Wolf’s “Console Chaos” research and other pivots with potential connections to the Core Werewolf (also known as PseudoGamaredon or Awaken Likho) threat actor group.
Fortinet Advisory
I spilled my coffee a bit when I first looked at the Fortinet advisory mentioning the usual suspects — loopback addresses and Google DNS. But then re-reading the advisory and these in context gave me some perspective and understood why it was mentioned. While acknowledging the context in which these can be important but ignoring the “values”, I focused on the other IOCs in the report.
Thanks for reading! Subscribe for free to receive new posts and support my work.
Understanding Infra Analysis
Infra-analysis is not entirely part of threat hunting but it aids in threat hunt research. So the scope of it is different from let’s say a threat intel OR cybercrime analyst. This analysis helps us to examine how systems, services, and networks that adversaries may use to conduct their operations and help us understand:
Tools and techniques adversaries use within a cluster or campaign
Operational patterns and preferences
Potential connections to known threat actors/group’s clusters/campaigns
In this article, I will focus on several “breadcrumbs” of infra analysis we can follow:
1. Service Fingerprinting: Examining unique identifiers of services running on different ports
2. Historical DNS Resolution: Understanding domain name patterns and relationships
3. SSL Certificate Analysis: Identifying relationships through shared certificates
4. Network Patterns: Looking for patterns in how services are deployed
5. ASN Patterns: Understanding the adversary’s preferred hosting providers and regions
Note: Adversary infrastructure tracking is complex with several layers within the group and between groups. So, the connections we make solely based on network observables may not be accurate to “make” connections. That being said, it is still valuable to understand suspicious ASNs, “commonalities” between groups, tools we uncover, and several other reasons.
All this to say, take this with a grain of salt in terms of “connections” but enjoy the things we uncover and learn along the way.
Pivoting structure
I would like to have some structure so we can expand our pivots to multiple points while still validating them. Here is my approach from Threat Hunt perspective.
1. First-Order Analysis: “Staying close to the source”
I prefer direct IOCs from the primary source that kicked off the analysis (Fortinet advisory)
Identify ports and services and pivot from there
Check SSL certificates to find past and future patterns
2. Correlation: For any additional references we find for the above, we should
Check the findings and timeframes of the research
validate TTPs if available
3. Expand Infrastructure:
Use the patterns to see if we can find similar infrastructure (not all here can have high confidence unless there are solid connections)
Check historical DNS, certificate, and ASN data from the previous two steps
We are talking about the same thing: Arctic Wolf
when searching for IOCs from Fortinet’s advisory, I came across Arctic Wolf’s “Console Chaos” blog and saw three IP addresses matched. One thing I always like to check is if they are connected to each other by analyzing TTPs — which matched too in this case. So, we can connect words we initially observed like “exploited in the wild” to actual findings from the intrusion set. This is not technically a pivot but it is always good to correlate our dataset with multiple sources.
My failures: VPS Scanning Infra
I started digging into the overlapping IPs but it did not reveal much as most of these IPs were on VPS providers like DigitalOcean and Datacamp, and from the “Console Chaos” blog, these are connecting to the HTTP interface for likely confirmation purposes.
1. 45.55.158.47 has below both do not provide any more pivots just from these fingerprints:
45.55.158.47 (DigitalOcean):
- Primary Purpose: Reconnaissance
- Service Configuration:
- Port 22: SSH (Fingerprint: cb889df05d1536cc39938ac582e1eca1090e3662a270abff55ca6b119f2f11e0)
- Port 3306: MySQL (Fingerprint: e77fd0556cd803fa2613509423aaa86d34dda37e19cc2cfce7145cd9b1f5ff6a)
It’s the same for 37.19.196.65 and 155.133.4.175 and a few others. We like to see results in infrastructure analysis from all pivots but most of the time we just don’t or we may find something irrelevant.
Moving on the list, 157.245.3.251 has some interesting pivots although did not produce solid results.
- Operating System: Ubuntu Linux
- Service Layout:
- Multiple SSH services (both standard and non-standard ports):
- Port 22 (Standard)
- Port 222 (Alternative)
- HTTP services via Nginx on high ports (30000–30005)
- Historical ports (2024–09–09 and 2024–09–10): 9527, and 9530 returned empty responses but the timeframe was still in our research range.
We can craft a query to find everything on those ports and return empty responses but I did not find any. Regardless, it is an interesting pivot we can query in the future, in case it returns back.
(((services.port:{22,30002,30003,30004,30005})
AND (services:HTTP and services:SSH))
and autonomous_system.name: "DIGITALOCEAN-ASN"
and services.banner_hashes: "sha256:97f8ff592fe9b10d28423d97d4bc144383fcc421de26b9c14d08b89f0a119544"
and services.tls.certificates.leaf_data.issuer_dn: "C=US, O=Let's Encrypt, CN=R11")
and services.software.vendor='Ubuntu'
This query is to identify infrastructure with a similar pattern:
- Multiple HTTP services on specific high ports
- SSH presence
- Specific SSL certificate patterns
- Ubuntu-based systems
USPS Phishing Infra
When looking at 23.27.140.65, I found what looked like a USPS phishing lure from historical domains. This can be of interest here as it could be either for phishing for initial access with a focus on package tracking themes from the group itself or usage of possible Initial Access Broker (IAB) for that purpose. It’s hard to tell just from network observables but nonetheless, we have 102 domains used in the past 9 months.
- Timeline: July-December 2024
- Target Focus: USPS-related services
- usps.packages-usa[.]com
- usps-do-track[.]com
- usps.packages-ui[.]com
- and many more
The Core Werewolf Connection:
My most interesting discovery so far related to a previous campaign was the investigation of 31.192.107.165 (ORG-LVA15-AS). According to bi-zone, this network observable was previously linked to Core Werewolf (around October 2024), which matched our timeframe, too.
I spent some time looking for patterns mentioned in the blog in the same ASN and found about 49 IP addresses running Telegram-related content (one of the C2 mentioned).
Some other things that stood out are related to Silver C2 and Bulletproof services.
- 3524 results — not all possibly related to the infrastructure but a few interesting ones I found related to silver C2 and about 2,216 are from bulletproof services.
Staying within our bounds
149.22.94.37 revealed connections to an executable on VT
PDF-themed executables probably via SEO Poisoning (PDFs Importantes.exe)
Persistence via Registry modification for startup:
What does this mean? Well, nothing, because if we check the creation date 2017–03–26 05:14:46 UTC and submission date 2020–09–25 15:34:52 UTC, it is far off from our research bounds and might be linked to some other cluster/campaign. Can there be a connection? Probably. Can we make that connection now? Well, no, because of the timeframe and no other evidence to support it.
Infrastructure Relationship thus far
The investigation revealed several distinct but possibly (some are very distant) interconnected infrastructure components:
1. Scanning: for target identification and reconnaissance
2. Phishing: Likely for credential harvesting and initial access
3. C2: Things we can look to connect in the future or at least have them in our dataset to extract more insights like C2 configs, ports, etc
4. Campaign: Core Werewolf (AKA PseudoGamaredon, Awaken Likho) threat actor group relationship during the same timeframe. It requires additional patterns and observables to strengthen our intuition.
It’s the timing
In the middle of all this, I came across a social media post from “Belsen_group” claiming to have credentials and configs. They published this as “free” and organized it via country “to make it easier for you”. I checked their site and the data to get an overall sense to see if it is related to current exploitation. I will not go a lot into it as Kevin Beaumont beat me to it. According to Kevin, these are from 2022 for CVE-2022–40684 exploitation and not this one. It’s just the timing and you can find the article at https://doublepulsar.com/2022-zero-day-was-used-to-raid-fortigate-firewall-configs-somebody-just-released-them-a7a74e0b0c7f
Several passwords I observed, one might say, are weak in nature. They are mostly have patterns of
1. Simple 4–8 char
2. Passwords are a variation of the username of variation of VPN
If nothing is related, why publish this? My only intention was to provide how infra analysis can help threat hunters at times and show what I’ve learned:
1. Patience — a lot of dead ends, so, stay focused
2. Finding pivots — No pivot is a sure shot and staying in bounds during our pivots. We should always understand why infra is structured in certain ways and how it can be used.
3. Using multiple data sources — certificates, DNS records, and service fingerprints from multiple platforms is always a good idea.
For anyone starting out in infrastructure analysis, remember to document everything (especially the failures) to help in the future and stay excited.
Recently, after discussions with folks, I realized there may exist few challenges in threat hunting, especially related to threat hunt research. These folks understand that threat hunting is a proactive approach to uncovering threats, but they feel their approach is scattered and inefficient, leading to inconsistent results despite spending much time. They felt every hunt was like starting from scratch and were unable to build from their previous hunts or scale their process effectively. I think one of the possible root causes might be the lack of a structured approach to threat hunting research. Without this structure threat hunting will become a game of chance rather than a systematic process.
But threat hunting research can be an efficient and repeatable process to deliver consistent results. To achieve that we need to understand and implement a structured methodology, especially for the research phase that can navigate us in all other phases of threat hunting process.
Threat Hunt research is all about figuring out how adversaries operate and approaches to uncover their presence but it is also the foundation to conduct effective hunts. It's a process of understanding adversary behaviors, mapping them to observable events, exploring hunt hypotheses, and understanding environmental factors with structured methodologies, frameworks, and approaches. Hunt research is the foundation that helps us (threat hunting teams) go from an ad-hoc activity into a repeatable, scientific process.
I will attempt to compare threat hunting research to DFIR (Digital Forensics and Incident Response) drawing from my experiences whenever possible.
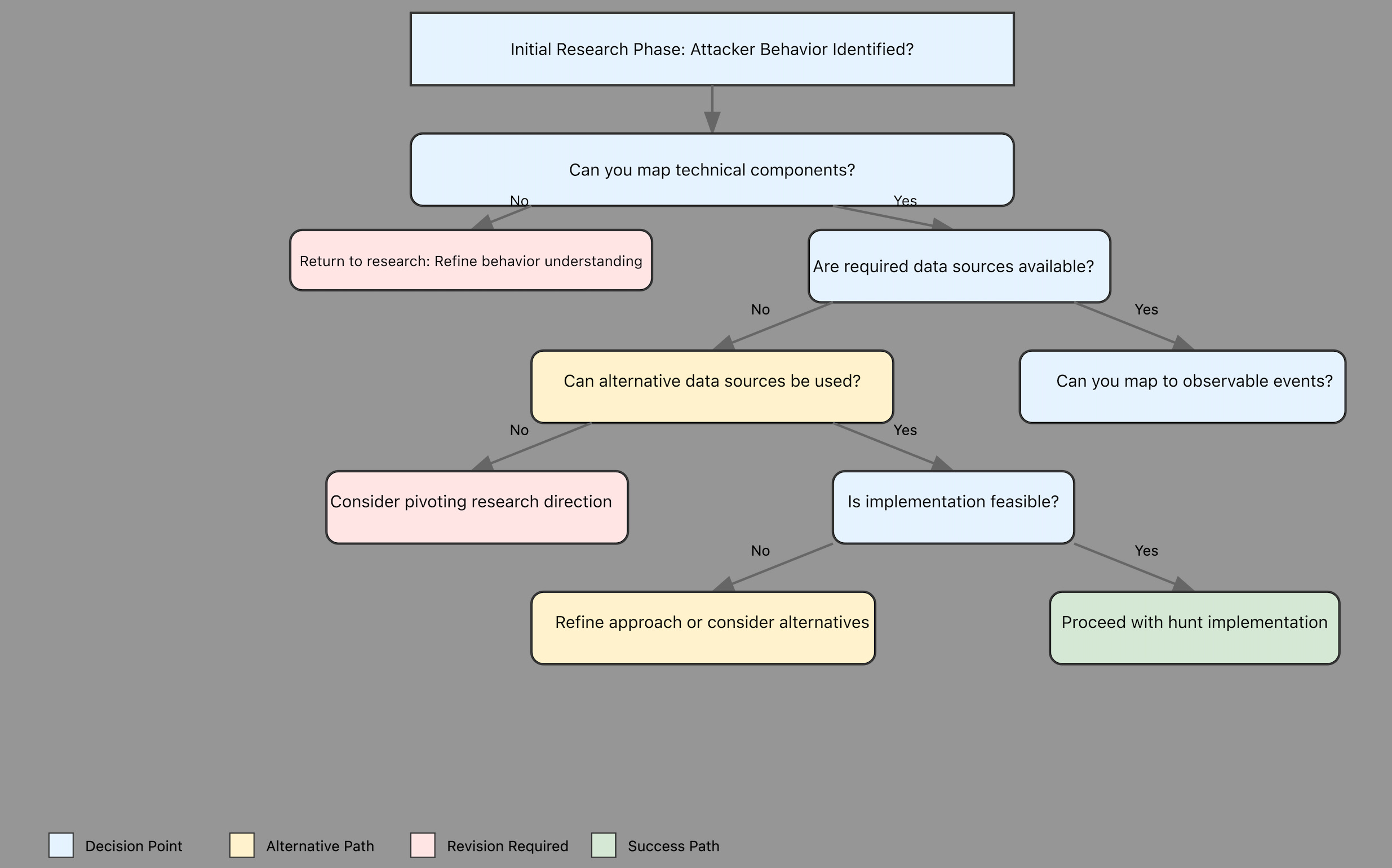
TLDR: Here is the diagram that might help you in threat hunting research
Threat hunting research is similar to Digital Forensics and Incident Response (DFIR), in the latter folks look into incidents after they happen and the former find patterns before potential breaches or try to identify patterns deviating from the environmental norms. But the way we investigate is similar. Knowing these similarities can help us better approach threat-hunting research.
1. Initial Research
Just like DFIR investigators plan their investigations before they start, the hunting research phase starts by planning and thinking about what they might find (consider the A.P.E.X. framework to see how). In DFIR, investigators might ask, What systems were probably compromised? and What clues would show that they were?
Similarly, in threat hunting research we should ask,
What specific attacker behavior am I investigating?
What does the attack chain look like?
What technical components make up this behavior?
What does a successful execution of this behavior look like?
The planning phase is important for both because it helps us understand the overall picture. DFIR investigators create timelines of events and figure out the scope/pivots, while threat hunting research makes maps of the past attack patterns of an adversary and figures out the possible patterns of the adversary behavior in the future to formulate possible hypotheses, hunt pipeline to better assist/enhace existing detections.
2. Data Source Analysis:
DFIR investigators find and record important evidence when they investigate an incident. They determine which sources, artifacts, and means might contain evidence of the incident. Threat hunting research do something similar when they examine data, but with a proactive twist. Teams sometimes spend too much time to figure out which data sources might contain relevant information at the time of the hunt. Instead, research should include a systematic approach to map adversary behaviors or patterns with relevant, available data sources and fields before even beginning the hunt. It will help us understand not just the data sources we need but the categories in those data sources along with their fields. We need to know:
Where the relevant data is in the environment
How the data is formatted and structured
How long it’s supposed to be kept and how it’s collected
How different data sources are related
3. From Artifacts to Activities:
While IR investigators piece together clues from various sources to figure out what happened during an incident, threat hunt research does the same thing, but in reverse. We try to guess what artifacts and patterns would be left behind by specific adversaries/techniques/tactics based on our hypothesis. The main difference is that DFIR looks back to figure out what happened, while we try to look forward to predicting future attacks. However, the intelligence gathered by both can help us understand attack patterns and use them to detect future attacks.
The key difference between hunters who feel like random searching and the ones who do structured hunting is hypothesis generation.
A good hypothesis in threat hunting research: (Check out the Hunting Opportunities section here)
Focuses on a specific attacker behavior or technique
Links to concrete, observable events in the environment
Accounts for variations in how the behavior might manifest
Considers the context of environment and normal operations
Includes clear criteria for validating or disproving the hypothesis
4. Environmental Analysis
DFIR teams need to know the environment they’re investigating which includes the network architecture, security controls, and business context (which might not apply to consulting or MSSP). In an effective threat hunting research, we know that no two environments are identical and what works in one organization might not work in another due to differences in:
Available data sources and logging configurations
Infrastructure complexity and distribution
The security tools that are deployed
The typical patterns of business activity
The limitations and blind spots in logging and monitoring
This understanding helps DFIR teams spot unusual activity and helps threat hunting research distinguish between normal and potentially malicious/suspicious activities. Knowing these environmental factors also helps us to develop both effective and efficient hunts.
Thanks for reading! Subscribe for free to receive new posts and support my work.
5. Documentation
DFIR investigations require extensive documentation – from initial findings through final conclusions. This documentation becomes a treasure trove for future investigations, helping teams spot patterns across multiple incidents. Threat hunting research is also not a one-time effort - it's an evolving process that builds upon itself which in turn refines methodology rather than specific incidents. Each hunt provides new insights, reveals gaps in visibility, and helps refine future hunting approaches. Maintaining detailed documentation of our research, including both successes and failures, is crucial for building a mature hunting program. Both types of documentation have some things in common:
Detailed technical findings and observations
Analyzing patterns and behaviors
Figuring out how different pieces of evidence are connected
Recommendations for future investigation or hunting
Research —> Hunt
The reason we did all the research is to hunt in our environment. It is also a catch-22 - Do we figure out what to research first and then hunt? or Do we figure out what to hunt and then kick off research? This transition from theoretical research to practical hunting is often time-consuming, and resource-intensive. It also requires several things to fall in place to bridge the gap between knowledge and action.
Clear documentation of hunting methodology - not observable
Specific queries or search parameters from the 2, 3, 4, and 5 steps
Success criteria and metrics
Plans for handling findings - from clear security incidents to suspicious but irrelative (to our hypothesis) findings to new hunts
Validation
DFIR teams and threat hunting researchers both know that false conclusions can be expensive. They both validate their findings through multiple data sources and analysis techniques - sometimes it requires simulating the behavior in a test environment. Threat hunting research requires thorough validation of hypotheses and methodologies.
Testing assumptions, queries, and hunt methods against known-good data or "normal behavior"
Verifying findings through multiple sources along with observable events actually indicate the behavior we are hunting for
Considering alternative explanations
Documenting limitations and caveats
Adaptability
Just as DFIR teams must adapt their techniques/methodologies to new types of attacks, evolving tech, and complex environments, threat hunting research needs to keep getting better. Both face similar challenges:
Changes in attacker techniques and tools
Evolution of enterprise technology and architecture
changes in security controls and monitoring
Building flexibility into our research methodology allows us to:
evaluate new sources of evidence and data
Scale across growing environments
Integrate new tools and technologies or refine the ones according to our requirements.
Conclusion
Hopefully, this parallel between DFIR and threat hunting provided valuable insights into threat hunting research. Both require systematic approaches, detailed technical understanding, and the ability to adapt to changing circumstances. By applying a similar standard methodology of DFIR to threat hunting research, organizations can make their hunting programs even better. There is always room for creativity and innovation in this structured approach and methodologies as threat hunting is both an art and a science.
In a laest report I worked on Hunters International ransomware, I provided several hypotheses you can implement in your environment. I want to reiterate the importance of integrating environmental context with threat actor profiling, a crucial aspect of threat hunting. I want to re-introduce the A.P.E.X. framework, which we used in our other threat reports, and delve a little deeper into its implementation with an example. A.P.E.X. hypothesis generation framework is a comprehensive methodology I developed internally for hypothesis generation. It is
Four-Element Structure:The A.P.E.X. framework integrates both perspectives through four key elements: Analyzing the environment, Profiling threats, Exploring anomalies, and examining X-factors (unexpected variations). This integration proved crucial in our investigation. The framework offers a structured, and adaptable methodology that aids threat hunters in generating hypotheses for both known and emerging trends.
X-Factor Consideration:A.P.E.X. explicitly accounts for unexpected or unexpected threat techniques through its X-factor element. This approach hopes to help hunters account for emerging threats.
Hypothesis Generation:A.P.E.X. offers a structured approach to creating both primary and focused hypotheses, providing more granularity and direction for threat hunters.
Expected Observations:For every hypothesis, A.P.E.X. outlines detailed expected observations, categorized into standard (E) and unexpected (X) observations. This can also be translated into success criteria.
Integration of Multiple Techniques:The framework takes various threat-hunting "techniques", including hypothesis-driven hunting, anomaly detection, and threat intelligence integration.
Theory to Practice:
A.P.E.X. can be used to generate the following hypothesis:
"Attackers are exploiting Oracle WebLogic debug ports for initial access."
A (Analyzing the environment):Oracle WebLogic servers were present in the environment, and debug ports were potentially exposed.
P (Profiling threats):Hunters International has shown a pattern of exploiting web server vulnerabilities.
E (Exploring anomalies):The unusual connections to port 8453 (WebLogic debug port) were noticed in the network logs.
X (X-factor):Attackers might use novel exploitation techniques or zero-day vulnerabilities.
Expected Observations:
E1:Connections to port 8453 from external IP addresses.
E2:Execution of Java processes with debug parameters.
E3:Creation of web shells or other backdoors post-exploitation.
X1:Unusual Java class loading or reflection activities indicating a new exploitation method.
X-factor consideration leads to unique insights:
We explicitly included the X-factor in the overall hypothesis generation process to account for novel or unexpected attacker behaviors based on patern-projections. This approach allows threat hunters to project and hunt emerging threats that may not fit already established patterns observed. In this case, it helped us discover an exploitation technique for Oracle WebLogic servers. Considering beyond known tactics, techniques, and procedures (TTPs), the X-factor enables a more forward-looking threat-hunting approach. While monitoring for expected observations (E1-E3), we also looked for X1 - unusual Java activities. This led to the finding of a previously unknown method of exploiting WebLogic.
Attackers used a custom Java class to execute arbitrary code.
We observed unusual Java class loading patterns that didn't match known exploit techniques for the group.
This approach generated specific, actionable observations and helped track the other activities in the attack lifecycle:
E1:Connections to port 8453 helped identify potential initial compromise, scoping, and timeline.
E2:Execution of Java processes with debug parameters revealed the attacker's method of maintaining access.
E3:The creation of the "Intel" folder and China Chopper web shell was detected allowed us to identify compromised systems quickly.
X1:Unusual Java class loading was observed, indicating a potential new exploit technique.
By following these detailed observations, I was able to track the attack progression from initial access through lateral movement and ultimately to the ransomware deployment, providing a comprehensive view of the Hunters International operation and enabling more effective intrusion analysis and hunting strategies.